第一步,下载Ollama框架
在本地跑开源大模型,目前最好的软件肯定是Ollama。
不管你用的是PC、Mac,甚至是树莓派,都能通过Ollama运行大大小小的模型,而且扩展性极强,几乎没有什么设备不兼容。
安装Ollama超级简单。到官网ollama.com或者ollama.ai下载对应版本就行。
官网下载链接:https://ollama.com/download/windows ,根据你的系统选择对应的版本,下载后安装,安装完成后在系统托盘能看到一个羊驼图标,恭喜你,你完成了第一步(应该不会有人连第一步都完成不了吧?如果你连第一步都完成不了,请按CTRL+W)
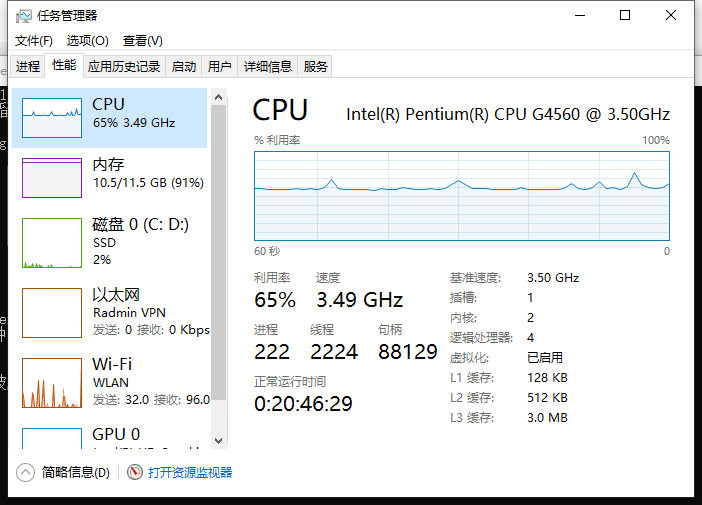
性能要求很低,你就算没有显卡也能运行,就比如我的电脑CPU是G4560无独显,跑Gemma2 9B慢了点,但20分钟内肯定能回答完。
第二步,下载你心仪的AI大模型
如何安装模型?在这上面搜索:https://ollama.com/search ,找到心仪的模型后到它的详情页,选择你要的型号,复制旁边的命令,Win+R打开CMD(不会开CMD自己搜一下,反省一下),右键粘贴命令安装
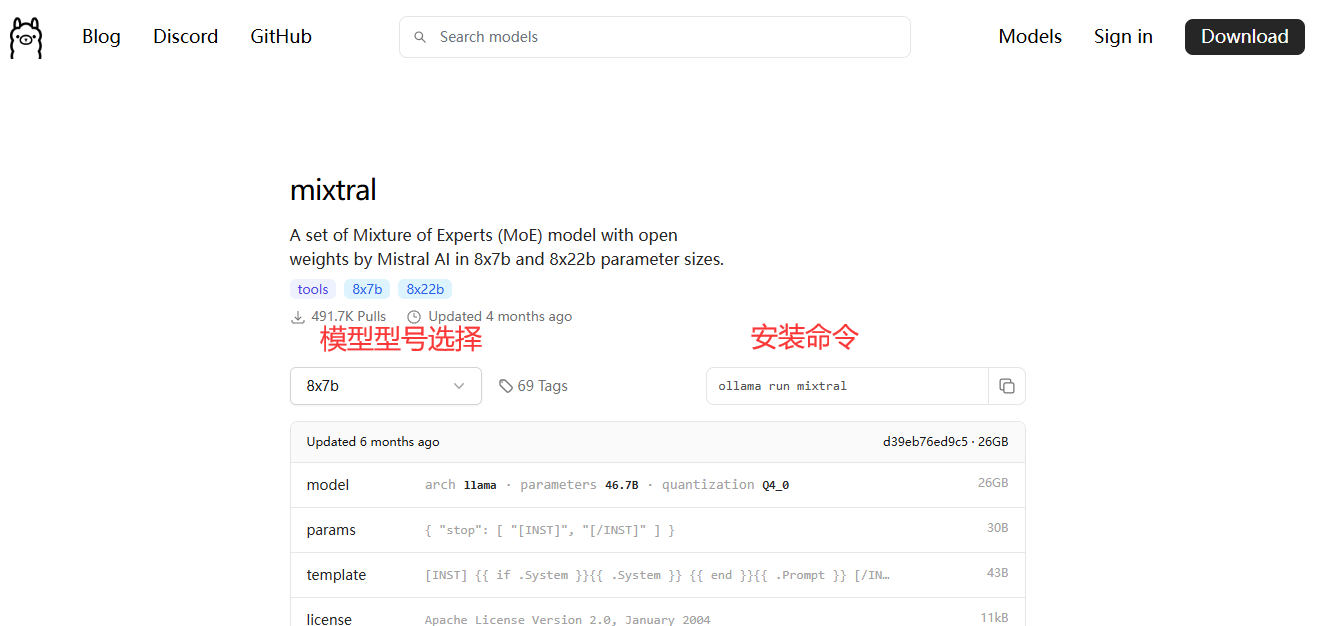
安装命令格式为:ollama pull 模型名 ,运行命令ollama run 模型名 ,停止命令ollama stop 模型名 ,删除命令ollama rm 模型名
(注:你直接使用ollama运行未下载的模型时会自动下载,下载完自动运行)
一般来说,7b的模型至少需要8G RAM,13b需要16G,70b需要64G。大家量内存而为,不然跑起来真的非常卡顿。(因为要不断的读盘)
以下是一些常用的模型,推荐选择
Gemma2 (中规中矩,表现优秀,我的电脑跑9B两三秒吐一字)安装命令ollama run gemma2
phi2 (低配机福音,吐字飞快,可惜不会中文,我的一秒三四个单词)安装命令ollama run phi
mixtral (土豪用的,有8x7b和8x22b两款,22GB和80GB,我的电脑跑不动,嘶~~)安装命令ollama run mixtral
| 模型 | 参数 | 大小 | 模型名 |
|---|---|---|---|
| Gemma2(谷歌推出的,配置不差的家用电脑推荐用它) | 9B | 5.5G | gemma2 |
| phi2(微软推出的,4 GB 内存即可运行,吐字速度飞快,不懂中文) | 2.7B | 1.6G | phi |
| Llama3.1 | 8B | 4.7G | llama3.1 |
| Llama3.1 | 405B | 231G | llama3.1:405b |
| GLM4 | 9B | 5.5G | glm4 |
| Qwen2 | 7B | 4.4G | qwen2 |
| Qwen2 | 72B | 41G | qwen2:72b |
| Llama3 | 8B | 4.7G | llama3 |
| Llama3 | 70B | 40G | llama3:70b |
| Phi3 | 3.8B | 2.3G | phi3 |
| Phi3 | 14B | 7.9G | phi3:medium |
| Gemma2 | 27B | 16G | gemma2:27b |
| Mistral | 7B | 4.1G | mistral |
| Starling | 7B | 4.1G | starling-lm |
| CodeLlama | 7B | 3.8G | codellama |
| LLaVA | 7B | 4.5G | llava |
| Solar | 10.7B | 6.1G | solar |
安装完了吧?装完了往下看
第三步,运行大模型,并与之对话
使用ollama run 模型名运行你下载的大模型并与之交互式对话,你也可以用ollama run 模型名 "你的问题"来问问题,该命令不会进入交互式输入模式。以下是我的电脑跑Gemma2的效果和性能开销,在跑的时候CPU占用60%左右

你以为折腾这些就只能聊天吗,不止!往下看!
在生活中运用大模型
在此之前,你可以给Ollama开启跨域访问功能(Ollama默认API只能用127.0.0.1访问,要在别的电脑上使用需要设置跨域访问,若你只想在当前电脑上使用则跳过当前步骤)
设置跨域访问
- 右键此电脑图标,点击属性
- 在系统关于界面,下滑到最下面,点击高级系统设置
- 在弹出的窗口中点击环境变量
- 在上方的用户环境变量新建两个用户变量,变量名OLLAMA_ORIGINS和OLLAMA_HOST,变量值设为*和0.0.0.0:11434。
- 按确定保存,然后在托盘找到羊驼图标,右键退出重新打开
1.网页翻译
请使用Gemma2模型,Phi不会外语
先安装沉浸式翻译插件:https://immersivetranslate.com/zh-Hans/
安装好后到插件设置里,点击翻译服务,将其他的服务都关掉,将OpenAI设为默认,然后点击OpenAI名字进到设置,将沉浸式翻译API改为自定义API Key,API Key随便输几个字,自定义接口地址协议从https改成http,将地址改为http://你的IP/v1/chat/completions。这里IP设置成你的IP,如果服务在本机运行可以设置成127.0.0.1,然后勾选输入自定义模型名称,将其改为你运行的模型名,最后拉到最上面,点击“点击测试服务”,提示验证成功你就大功告成了。
如果遇到问题,欢迎留言反馈!

 门罗币钱包地址47JGXgtfPvANa9b29RfGEGRpCsK6
门罗币钱包地址47JGXgtfPvANa9b29RfGEGRpCsK6
